Самое актуальное и обсуждаемое


Популярное

3д тюнинг
Тюнинг-ателье или игра?
Представляем вниманию две программы, которые имеют свою базу автомобилей, свои...
83
0
0

15 лучших хэтчбеков
5 LADA Granta хэтчбек
Рестайлинговая LADA Granta стала больше похожа на автомобиль старшего семейства...
118
0
0
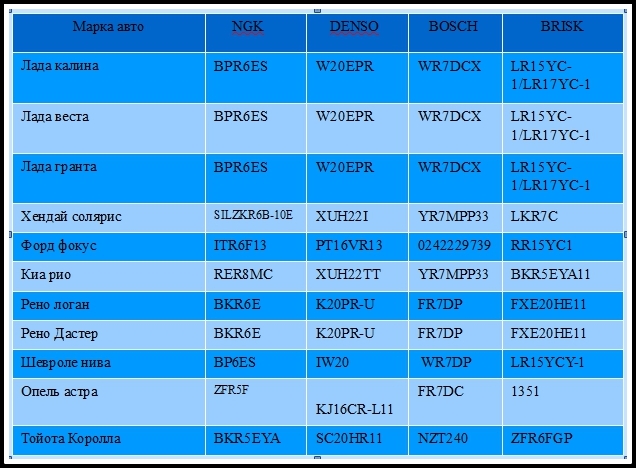
14 лучших производителей свечей зажигания
Коротко о главном: информация для автомобилистов
Главное предназначение свечей зажигания – воспламенение...
123
0
0

12 самых надежных микроавтобусов
Микроавтобусы Volksvagen – надежная современная техника для российских дорог
Популярное решение вопроса...
104
0
0

25 лучших классических маслкаров
Мускулы в консервной банке
Эра масл-каров началась в 1964 году, когда с конвейера сошел первый Pontiac...
67
0
0

10 причин, почему автомобиль отказывается заводиться: список
Не заводится машина с бензиновым двигателем
Что делать, если машина не заводится
https://www.youtu...
96
0
0

21124 двигатель на что ставят
Неисправности и ремонт двигателя ВАЗ 2112
Двигатель ВАЗ 2112(21103) это качественная эволюция мотора...
79
0
0

27 лучших семейных автомобилей
Рейтинг лучших седанов
Седаны – самые распространенные частные транспортные средства. Преимущество –...
79
0
0
Полезные советы

Важно знать!
15 лучших коммерческих автомобилей
Правильная покупка коммерческого автомобиля с рук
Приобретение подержанной машины среднего класса с пробегом не слишком сложная процедура. Следует помнить о важных моментах, касающихся технического состояния...
Читать далее
1 моточас
20 лучших всесезонных автомобильных шин
20 лучших автомагнитол
1g fe. двигатель тойота
15 лучших минивэнов
13 полезных инструментов для автомехаников и гаражных мастеров
8 потрясающих автомобилей-самоделок, которые люди собрали в гараже
8 самых известных типов двигателей в мире и их отличия
10 спортивных машин стоимостью до 7000$
Рекомендуем










Лучшее

Важно знать!
10 самых тихих зимних шин
Топ-5 самой тихой зимней резины
Зимние покрышки отличаются более высоким уровнем издаваемого шума. Особенно громкими считаются шипованные шины. Но и здесь конструкторы ведущих мировых брендов проявляют...
Читать далее
2 схемы
5 лучших методов устранения царапин на пластике в салоне автомобиля
27 легендарных советских автомобилей: на чём ездили в ссср
9 важных фактов про datsun on-do (теперь
10 лучших летних шин r14
54 дроссель: установка на ваз 2114
15 самых дешевых автомобилей в россии
10 лучших герметиков для шин
4 варианта тюнинга шевроле ланос: способы, актуальные идеи
Новое









Обсуждаемое

Важно знать!
95 экто или евро: стоит ли платить за разницу?
Стандарт Евро: характеристика топлива 95-Евро
Одной из главных тенденций последних десятилетий является сохранение экологии. Нефтеперерабатывающая промышленность пересмотрела технологии производства бензина,...
Читать далее
Популярное








Актуальное

Важно знать!
10 лучших колонок для авто (16 см)
Размеры
Сперва необходимо определить, каких именно габаритов будет устройство. Самое главное – это то, чтобы колонки максимально подошли по размеру к штатным отверстиям в салоне автомобиля. В противном...
Читать далее
10 лучших автошампуней
5 надежных авто за 350 тысяч в 2021!
15 лучших автомобилей с большим багажником
10 способов выкрутить винт с сорванными шлицами
10 интересных фактов о бренде smart
20 редких советских автомобилей
5 ярких лампочек в фары авто с алиэкспресс
9 лучших автоэмалей
10 лучших гонок на пк
Обновления
 Статьи
Как отремонтировать глушитель холодной сваркой?
Статьи
Как отремонтировать глушитель холодной сваркой?
Способы ремонта глушителей
В зависимости от сложности проблемы выбирается и один из способов ремонта...
 Статьи
Поиск авиабилетов по всем авиакомпаниям и где лучше отдыхать в Турции
Статьи
Поиск авиабилетов по всем авиакомпаниям и где лучше отдыхать в Турции
Все мы сталкивались с утомительным, многократным поиском при попытке забронировать самые дешевые...
 Статьи
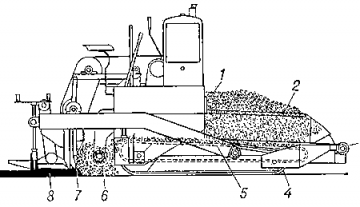
Технические характеристики асфальтоукладчика
Статьи
Технические характеристики асфальтоукладчика
Применение катка:
Дорожный каток незаменим в таких отраслях, как строительство и ремонт дорог. Аренда...
 Статьи
Лучшие сервисы аренды автомобилей
Статьи
Лучшие сервисы аренды автомобилей
Вам нужно арендовать автомобиль для следующего отпуска? Перед бронированием ознакомьтесь со следующими...
 Статьи
Видеокарта для компьютера — как правильно выбрать
Статьи
Видеокарта для компьютера — как правильно выбрать
Производительная видеокарта — это возможность не только запускать современные игры на максимальных настройках,...
 Автомобили
Топ-12 лучших внедорожников
Автомобили
Топ-12 лучших внедорожников
Лучшие средние внедорожники
Средние внедорожники в большинстве тоже относятся к компактным кроссоверам,...
 Автомобили
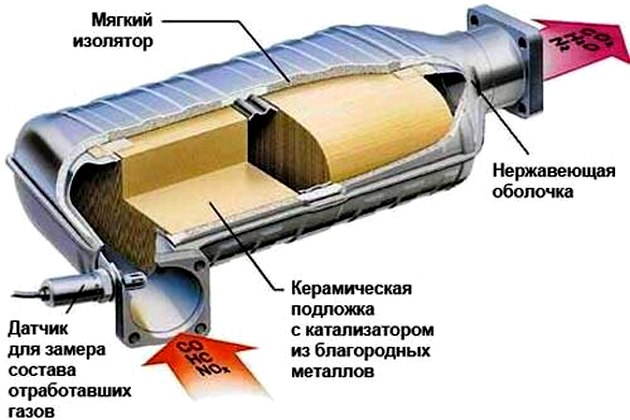
Автомобильный катализатор: что это такое и что ценного в нем, признаки неисправностей и их устранение
Автомобили
Автомобильный катализатор: что это такое и что ценного в нем, признаки неисправностей и их устранение
Какова роль катализатора в автомобиле?
Интенсивное развитие автомобильной промышленности и растущее...
 Автомобили
Шевроле niva
Автомобили
Шевроле niva
Рестайлинг 2009-го года
В 2009-м году автомобиль перенес рестайлинг, повлекший за собой новую внешность...
 Автомобили
Второе поколение nissan juke 2020 обошедшее россию
Автомобили
Второе поколение nissan juke 2020 обошедшее россию
Экстерьер
Благодаря переезду на новую «тележку» CMF-B удалось существенно увеличить габариты автомобиля....
 Этандиол
Этандиол
Этиленгликоль – токсичный двухатомный спирт
Химическая формула данного простейшего многоатомного спирта...
 Автомобили
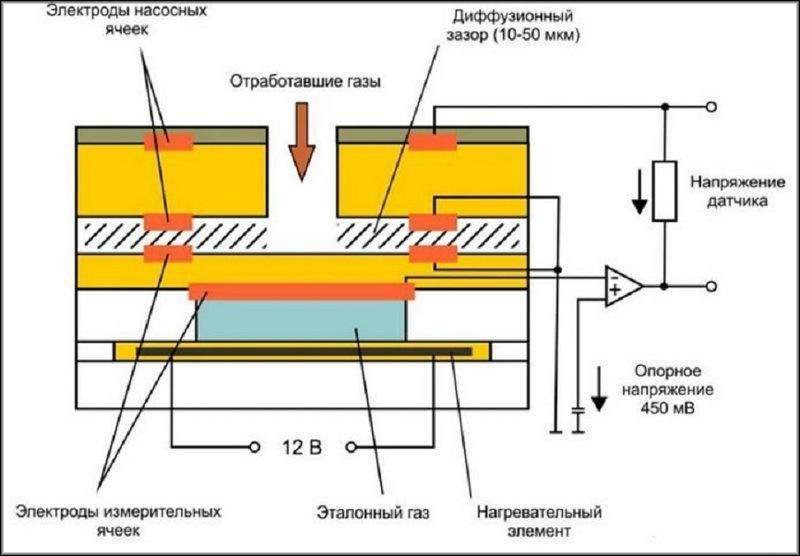
Лямбда-исчисление
Автомобили
Лямбда-исчисление
Вместо введения
Для начала определимся с терминологией: лямбдой мы называем lambda-expression – это...
 Автомобили
Ваз 2106
Автомобили
Ваз 2106
Технические характеристики ВАЗ 2106
Эксплуатационные характеристики ВАЗ 2106 шестерка
Максимальная скорость:...
Нашли ошибку, неточность или опечатку в тексте?
Выделите её и нажмите Ctrl + Enter
Выделите её и нажмите Ctrl + Enter